

Daniel Fernández Álvarez entrena a los ordenadores para que sean más “listos”. Para que sepan diferenciar cuándo el internauta solicita información sobre el Rey Juan Carlos (la persona) o la Rey Juan Carlos (la universidad). Para que cuando el usuario busque Fernando Alonso en internet, Google le responda con una imagen del piloto ovetense agarrando su casco de Fórmula 1...
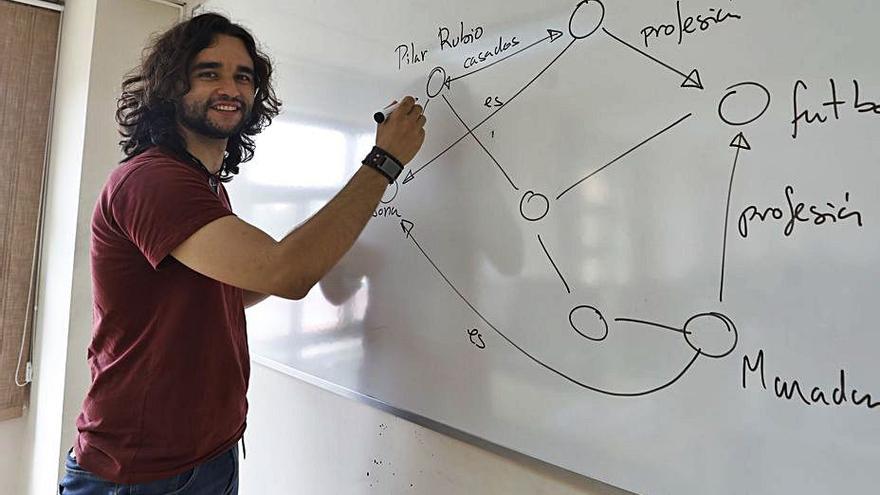
Y todo eso se consigue, dice este joven ingeniero informático, asignando a cada idea unos identificadores concretos y construyendo grafos –una gran red en la que muchos nodos se conectan entre sí– cada vez más complejos. “El objetivo de mi tesis es tender puentes entre lo que entienden los humanos y las máquinas, es decir, mezclar la web semántica y el lenguaje natural”, resume Fernández, ovetense de 29 años.
En este campo está casi todo por hacer, como remarcan sus directores de tesis, los profesores titulares del departamento de Informática José Emilio Labra Gayo y Daniel Gayo Avello. “Estamos quizá en su infancia. Si comparas la web con la historia de la humanidad estamos en los inicios. Y más todavía si hablamos de la web semántica”, aseguran. Pero en este corto espacio de tiempo se han producido grandes avances. Por ejemplo, señala Daniel Gayo, “antes Google para contestar te ofrecía miles de páginas; ahora, sin embargo, te da respuestas directas”. Como decirte que LA NUEVA ESPAÑA es un periódico al teclearlo en el buscador. Y eso que parece magia es en realidad el trabajo de miles de ingenieros. Entre ellos, el ovetense Daniel Fernández, que para su investigación ha colaborado de forma muy estrecha con Wikidata, el esqueleto de datos de Wikipedia.
La técnica más sencilla para que las máquinas sepan lo que los humanos queremos es asignar a cada idea un identificador, y así quitarle al lenguaje natural su ambigüedad. “Cuando creas millones de identificadores, puedes resolver preguntas muy complejas. Lo que hoy conocemos como inteligencia artificial se sustenta sobre los datos, en parte sobre el tipo de datos que producimos nosotros”, aclara Daniel Fernández. En este punto, los profesores José Emilio Labra y Daniel Gayo advierten de que las máquinas en realidad no aprenden, “el que aprende es el ingeniero”. “La máquina no sabe lo que hace. Sigue siendo igual de tonta”, señalan. Y al igual que un navegador GPS se confunde, Google también puede liarse en las respuestas. Así sucede cuando le interrogas por la llegada de los humanos a América. “Dependiendo de cómo se lo preguntes (humanos o personas) o en qué idioma lo hagas, te da una fecha distinta”, apostilla Gayo.
El trabajo de Daniel Fernández es a “larguísimo plazo”. Porque son muchas las cosas que quedan por enseñar. “Las máquinas tienen que saber diferenciar que esto es un número de teléfono, que aquello es un DNI, que esto otro es una fecha de nacimiento. Y toda esa información que nosotros damos por hecho, no es para nada trivial y hay que ir enseñándosela a los ordenadores”, comentan los investigadores. En todo ello juegan un papel fundamental los grafos, que es lo que, por ejemplo, explota una red social para hacer recomendaciones de alumnos o lo que hace un navegador GPS para calcular rutas. El reto de muchos ingenieros informáticos de todo el mundo es que esos grafos se rellenen automáticamente y que las propias máquinas detecten fallos y los corrijan. Solo Wikidata está formada hoy en día por 93 millones de nodos de información.
Este uso masivo de datos tiene, según los investigadores asturianos, sus aspectos positivos (“todo el conocimiento que generas”) pero también negativos (“reduces la privacidad”). Ellos prefieren quedarse, no obstante, con los primeros y ponen como ejemplo su aportación hecha durante la pandemia para “mejorar el conocimiento de la humanidad”. “Daniel ha diseñado una técnica, que se está utilizando a nivel mundial, y que permite analizar grafos relacionados con el covid. Esos grafos provienen en parte de extracción de información automática de 280.000 publicaciones relacionadas con el virus por parte de otros ingenieros. Si tienes que poner a un grupo de investigación a interpretar toda esa información, por ingente resulta inabarcable. De ahí la importancia de buscar nuevas técnicas. Y eso hicimos. De hecho, fuimos invitados a dar una charla a la Universidad de Stanford y está bien que esto se sepa para que la gente vea que también desde la Escuela de Ingeniería Informática estamos haciendo cosas para ayudar en la lucha contra el coronavirus”, reflexiona José Emilio Labra.
El ovetense Daniel Fernández está en la recta final de su tesis, que empezó hace seis años y prevé presentarla en 2022. Su gran vocación por la docencia le llevó a matricularse en el programa de doctorado, que realiza dentro del grupo de investigación WESO (Web Semántica Oviedo), formado por diez profesores y constituido en 2004. “Lo bueno de Informática es que hay trabajo en la empresa y mejor remunerado que la Universidad. La carrera investigadora en esta área resulta poco atractiva, por lo que si alguien hace el doctorado, como Daniel, suele tener la vista puesta en ser profesor”, indica Labra. Esa gran salida laboral se convierte en un “handicap” a la hora de formar grupos de investigación, a lo que se suma que en esta rama de la ingeniería los proyectos “son por lo general de solo un año”. “Es muy difícil conseguir financiación, y la que llega es fundamentalmente de fuera”, rematan Labra y Gayo.
Objetivo: mejorar la experiencia en la web
¿Qué investiga?
Su objetivo es tender puentes entre lo que entienden los humanos y las máquinas para que la experiencia en la web sea cada vez mejor. Dicho con otras palabras, para que los ordenadores contesten cada vez con mayor precisión a lo que el internauta pregunta. Eso se hace asignando a cada idea un identificador que permita quitarle al lenguaje natural su ambigüedad y buscar así piezas del contexto.
¿Por qué es importante?
Porque la web semántica está todavía en sus inicios (en la infancia) y el margen de evolución es aún muy grande e inimaginable.
¿Cómo se financia?
A través de una ayuda predoctoral “Severo Ochoa”, que el Principado concede cada año a los jóvenes investigadores más excelentes. Son, aproximadamente, unos mil euros mensuales. Daniel Fernández consiguió este contrato hace dos años y medio. Anteriormente, financió su investigación con proyectos del grupo WESO (Web Semántica Oviedo).








